cols_merge_uncert: Merge columns to a value-with-uncertainty column
Description
cols_merge_uncert() is a specialized variant of cols_merge(). It takes as
input a base value column (col_val) and either: (1) a single uncertainty
column, or (2) two columns representing lower and upper uncertainty bounds.
These columns will be essentially merged in a single column (that of
col_val). What results is a column with values and associated
uncertainties, and any columns specified in col_uncert are hidden from
appearing the output table.
Usage
cols_merge_uncert(
data,
col_val,
col_uncert,
rows = everything(),
sep = " +/- ",
autohide = TRUE
)Value
An object of class gt_tbl.
Arguments
- data
The gt table data object
obj:<gt_tbl>// requiredThis is the gt table object that is commonly created through use of the
gt()function.- col_val
Column to target for base values
<column-targeting expression>// requiredThe column that contains values for the start of the range. While select helper functions such as
starts_with()andends_with()can be used for column targeting, it's recommended that a single column name be used. This is to ensure that exactly one column is provided here.- col_uncert
Column or columns to target for uncertainty values
<column-targeting expression>// requiredThe most common case involves supplying a single column with uncertainties; these values will be combined with those in
col_val. Less commonly, the lower and upper uncertainty bounds may be different. For that case, two columns representing the lower and upper uncertainty values away fromcol_val, respectively, should be provided. While select helper functions such asstarts_with()andends_with()can be used for column targeting, it's recommended that one or two column names be explicitly provided in a vector.- rows
Rows to target
<row-targeting expression>// default:everything()In conjunction with
columns, we can specify which of their rows should participate in the merging process. The defaulteverything()results in all rows incolumnsbeing formatted. Alternatively, we can supply a vector of row IDs withinc(), a vector of row indices, or a select helper function (e.g.starts_with(),ends_with(),contains(),matches(),num_range(), andeverything()). We can also use expressions to filter down to the rows we need (e.g.,[colname_1] > 100 & [colname_2] < 50).- sep
Separator text for uncertainties
scalar<character>// default:" +/- "The separator text that contains the uncertainty mark for a single uncertainty value. The default value of
" +/- "indicates that an appropriate plus/minus mark will be used depending on the output context. Should you want this special symbol to be taken literally, it can be supplied within theI()function.- autohide
Automatic hiding of the
col_uncertcolumn(s)scalar<logical>// default:TRUEAn option to automatically hide any columns specified in
col_uncert. Any columns with their state changed to 'hidden' will behave the same as before, they just won't be displayed in the finalized table.
Comparison with other column-merging functions
This function could be somewhat replicated using cols_merge() in the case
where a single column is supplied for col_uncert, however,
cols_merge_uncert() employs the following specialized semantics for NA
handling:
NAs incol_valresult in missing values for the merged column (e.g.,NA+0.1=NA)NAs incol_uncert(but notcol_val) result in base values only for the merged column (e.g.,12.0+NA=12.0)NAs bothcol_valandcol_uncertresult in missing values for the merged column (e.g.,NA+NA=NA)
Any resulting NA values in the col_val column following the merge
operation can be easily formatted using sub_missing().
This function is part of a set of four column-merging functions. The other
three are the general cols_merge() function and the specialized
cols_merge_range() and cols_merge_n_pct() functions. These functions
operate similarly, where the non-target columns can be optionally hidden from
the output table through the hide_columns or autohide options.
Examples
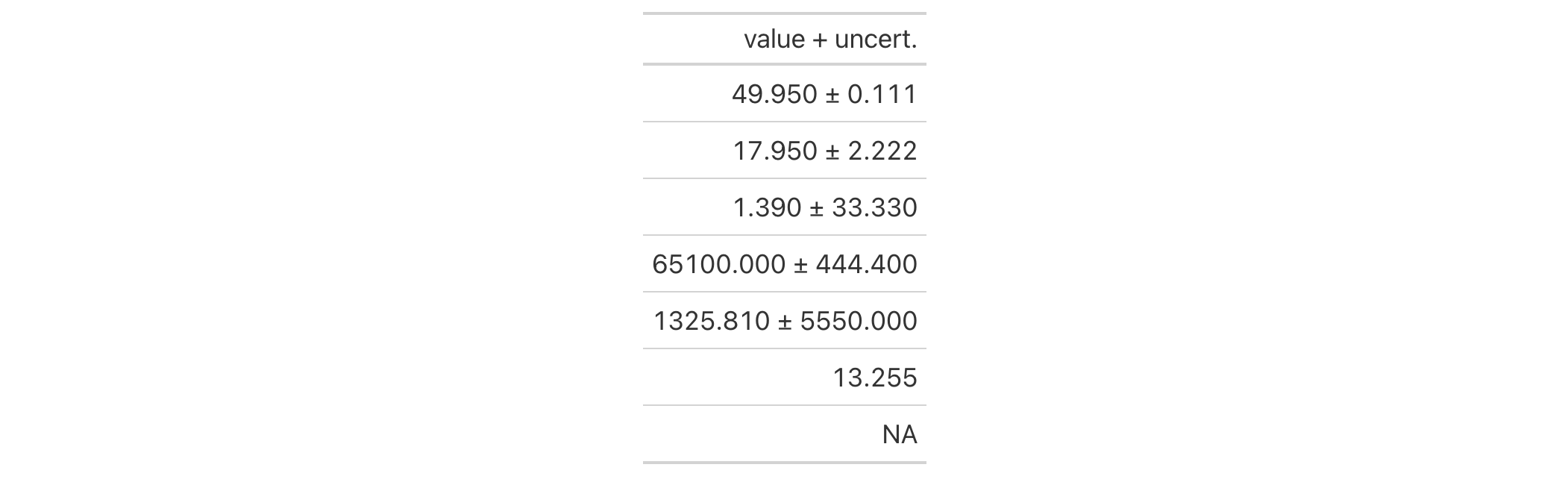
Let's use the exibble dataset to create a simple, two-column gt table
(keeping only the num and currency columns). We'll format the num
column with the fmt_number() function. Next we merge the currency and
num columns into the currency column; this will contain a base value and
an uncertainty and it's all done using the cols_merge_uncert() function.
After the merging process, the column label for the currency column is
updated with cols_label() to better describe the content.
exibble |>
dplyr::select(num, currency) |>
dplyr::slice(1:7) |>
gt() |>
fmt_number(
columns = num,
decimals = 3,
use_seps = FALSE
) |>
cols_merge_uncert(
col_val = currency,
col_uncert = num
) |>
cols_label(currency = "value + uncert.")
Function ID
5-15
Function Introduced
v0.2.0.5 (March 31, 2020)
See Also
Other column modification functions:
cols_add(),
cols_align(),
cols_align_decimal(),
cols_hide(),
cols_label(),
cols_label_with(),
cols_merge(),
cols_merge_n_pct(),
cols_merge_range(),
cols_move(),
cols_move_to_end(),
cols_move_to_start(),
cols_nanoplot(),
cols_unhide(),
cols_units(),
cols_width()