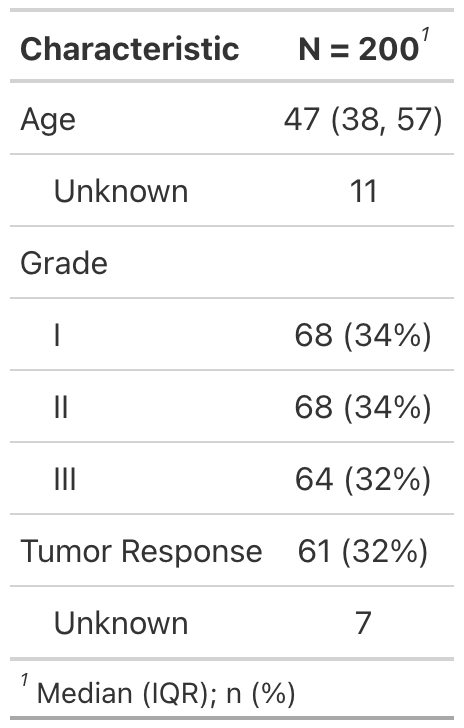
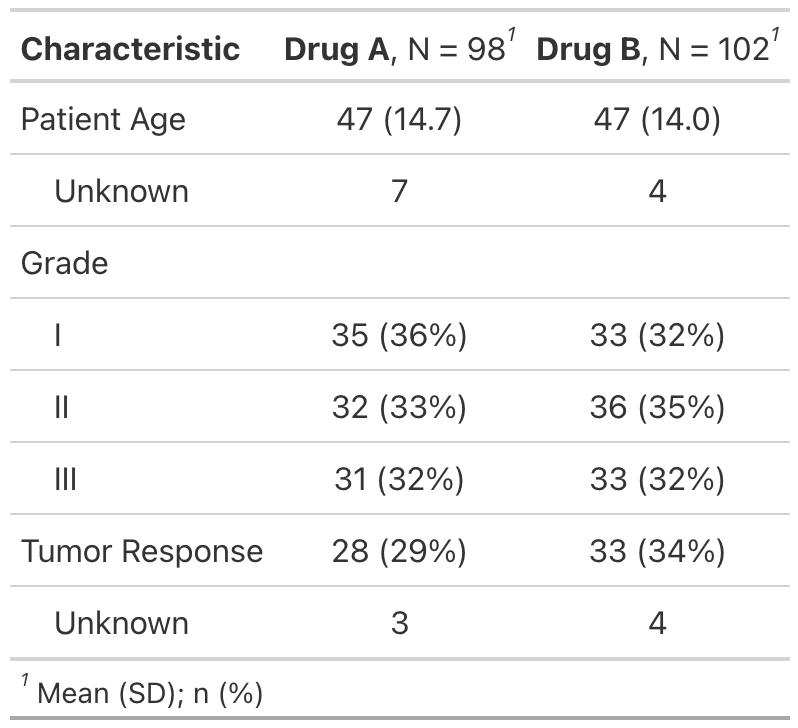
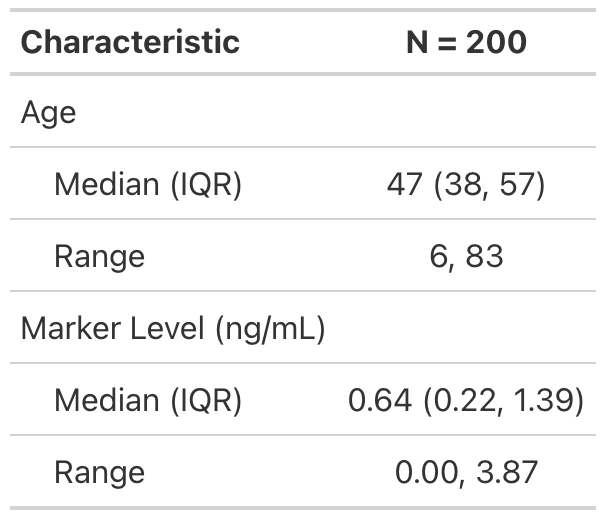
- data
A data frame
- by
A column name (quoted or unquoted) in data.
Summary statistics will be calculated separately for each level of the by
variable (e.g. by = trt). If NULL, summary statistics
are calculated using all observations. To stratify a table by two or more
variables, use tbl_strata()
- label
List of formulas specifying variables labels,
e.g. list(age ~ "Age", stage ~ "Path T Stage"). If a
variable's label is not specified here, the label attribute
(attr(data$age, "label")) is used. If
attribute label is NULL, the variable name will be used.
- statistic
List of formulas specifying types of summary statistics to
display for each variable. The default is
list(all_continuous() ~ "{median} ({p25}, {p75})", all_categorical() ~ "{n} ({p}%)").
See below for details.
- digits
List of formulas specifying the number of decimal
places to round summary statistics. If not specified,
tbl_summary guesses an appropriate number of decimals to round statistics.
When multiple statistics are displayed for a single variable, supply a vector
rather than an integer. For example, if the
statistic being calculated is "{mean} ({sd})" and you want the mean rounded
to 1 decimal place, and the SD to 2 use digits = list(age ~ c(1, 2)). User
may also pass a styling function: digits = age ~ style_sigfig
- type
List of formulas specifying variable types. Accepted values
are c("continuous", "continuous2", "categorical", "dichotomous"),
e.g. type = list(age ~ "continuous", female ~ "dichotomous").
If type not specified for a variable, the function
will default to an appropriate summary type. See below for details.
- value
List of formulas specifying the value to display for dichotomous
variables. gtsummary selectors, e.g. all_dichotomous(), cannot be used
with this argument. See below for details.
- missing
Indicates whether to include counts of NA values in the table.
Allowed values are "no" (never display NA values),
"ifany" (only display if any NA values), and "always"
(includes NA count row for all variables). Default is "ifany".
- missing_text
String to display for count of missing observations.
Default is "Unknown".
- sort
List of formulas specifying the type of sorting to perform for
categorical data. Options are frequency where results are sorted in
descending order of frequency and alphanumeric,
e.g. sort = list(everything() ~ "frequency")
- percent
Indicates the type of percentage to return. Must be one of
"column", "row", or "cell". Default is "column".
- include
variables to include in the summary table. Default is everything()